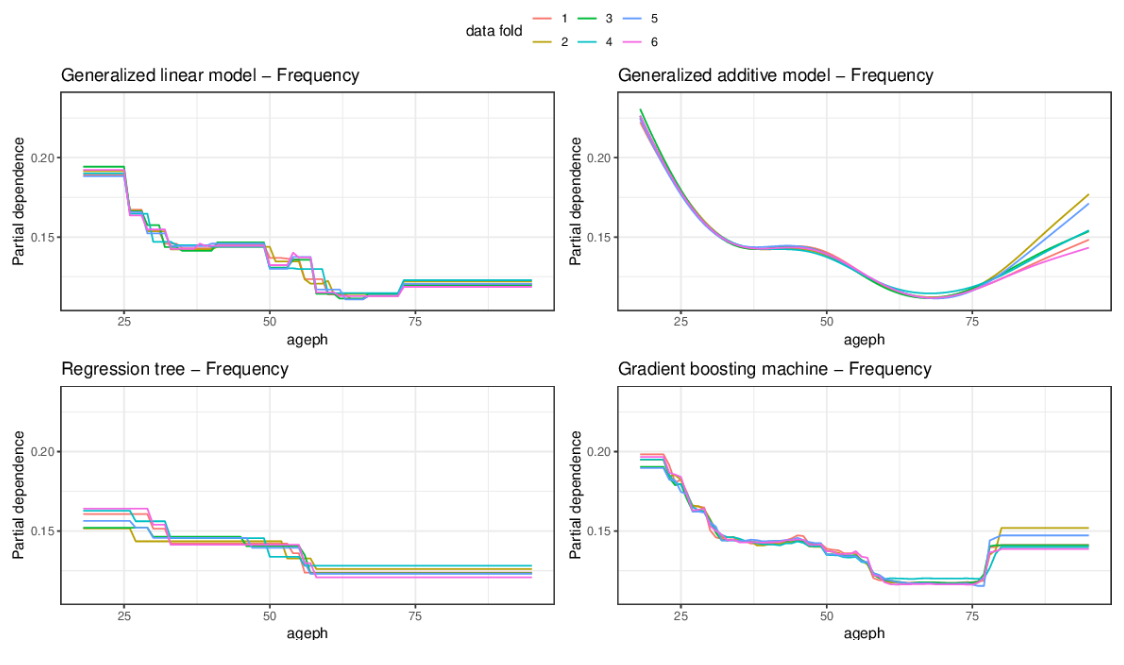
Abstract
Pricing actuaries typically operate within the framework of generalized linear models (GLMs). With the upswing of data analytics, our study puts focus on machine learning methods to develop full tariff plans built from both the frequency and severity of claims. We adapt the loss functions used in the algorithms such that the specific characteristics of insurance data are carefully incorporated: highly unbalanced count data with excess zeros and varying exposure on the frequency side combined with scarce but potentially long-tailed data on the severity side. A key requirement is the need for transparent and interpretable pricing models that are easily explainable to all stakeholders. We therefore focus on machine learning with decision trees: Starting from simple regression trees, we work toward more advanced ensembles such as random forests and boosted trees. We show how to choose the optimal tuning parameters for these models in an elaborate cross-validation scheme. In addition, we present visualization tools to obtain insights from the resulting models, and the economic value of these new modeling approaches is evaluated. Boosted trees outperform the classical GLMs, allowing the insurer to form profitable portfolios and to guard against potential adverse risk selection.